1. Introduction
2. Classification and logistic regression
3. Optimization methods
3.1 Stochastic / Gradient descent
3.2 Newton method
4. Regularization
1. Introduction
This note focuses on Supervised learning that using Linear regression model and Gradient descent algorithm to build the linear regression model.
Note: python, numpy, basic linear algebra, matplotlib are required. Please refer to this post and this post.
2. Classification and logistic regression
In this topic the prediction value y just takes on only a small number of discrete values. And we only focus on the binary classification problem in which $y \in \left \{ 0, 1 \right \}$. Applying linear regression algorithm to predict y given x, we need a hypothesis that can map y to {0,1}. We define:
$h(x) = g\left ( \theta ^{T}x\right ) = \frac{1}{1 + e^{-\theta ^{T}x}}\\
\text{where: }\\
\theta ^{T}x = \sum_{j=0}^{n}\theta _{j}x_{j} \text{ and } x_{0} = 1\\
g(z) = \frac{1}{1 + e^{-z}} \text{ is called logistic function or sigmoid function}$

$g(z)\rightarrow 1 \text{ when } z\rightarrow +\infty \\
g(z)\rightarrow 0 \text{ when } z\rightarrow -\infty \\
g(z) \in \left \{ 0, 1 \right \}$
Moreover, derivation g'(z) = g(z)(1 - g(z))
Change our perspective view to probability view. We consider:
$P(y=1|x; \theta ) = h(x) \text{ probability to y=1 given x, }\theta\\
P(y=0|x; \theta ) = 1 - h(x) \text{ probability to y=0 given x, }\theta\\
\text{or in compact form: } P(y|x; \theta ) = h(x)^{y}(1-h(x))^{1-y}\\
\text{assume m training examples are independent then we have }\\
P(y|x; \theta ) = \prod_{i=1}^{m}P(y^{(i)}|x^{(i)}; \theta ) = h(x^{(i)})^{y^{(i)}}(1-h(x^{(i)}))^{1-y^{(i)}}\\
\text{Apply the log likelihood. We define the log likelihood function:}\\
l(\theta ) = log(P(y|x; \theta )) = \sum_{i=1}^{m}(y^{(i)}log(h(x^{(i)})) + (1-y^{(i)})log(1-h(x^{(i)})))$
When predicting y=1 or y=0 we expect the maximum likelihood that y=1 or y=0. It means we maximize the log likelihood function. We can convert it to equivalent problem, that is minimize "-$l(\theta )$" (inverse problem by multiplying (-1)). We define the cost function:
$J(\theta ) = -l(\theta) = \sum_{i=1}^{m}(-y^{(i)}log(h(x^{(i)})) - (1-y^{(i)})log(1-h(x^{(i)})))$ and try to minimize it. In this post we focus on 2 methods that support to find theta that minimize the cost function: Stochastic / Gradient descent and Newton method.
Why this cost function is better than using 2-norm? If using 2-norm the cost function is not convex and it may have local minimum. While new cost function is convex and has one global minimum.

3. Optimization methods
3.1 Gradient descent
We calculate derivation of cost function
$\frac{\delta }{\delta \theta _{j}}J(\theta ) = (h(x) - y)x_{j}$
And then applying stochastic gradient descent rule using partial derivative of J ($\bigtriangledown _{\theta }J(\theta )$):
$\theta = \theta - \alpha \bigtriangledown _{\theta }J(\theta )\\
\text{where }\bigtriangledown _{\theta }J(\theta )=\begin{bmatrix}
\frac{\delta J(\theta )}{\delta \theta _{0}}\\
\frac{\delta J(\theta )}{\delta \theta _{1}}\\
...\\
\frac{\delta J(\theta )}{\delta \theta _{n}}
\end{bmatrix}$
Combine both and apply for 1 training example we have:
$\theta = \theta - \alpha(h(x^{(i)})-y^{(i)})x_{j}$
or batch gradient descent:
$\theta_{j} = \theta_{j} - \alpha\frac{1}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x_{j}^{(i)}$
Let 's make a demo using stochastic gradient descent. The input data is here.
Running this algorithm we see that it takes long time to archive minimum (on my machine it took more than 8 hours)

In order to find theta that maximize likelihood of cost function, we need to find theta so that $\frac{\delta }{\delta \theta _{j}}J(\theta ) = 0$.
The Newton method supports to find the value of x so that the function f(x) = 0 by applying repeating calculation:
$x _{t+1} = x _{t} - \frac{f^{'}(x)}{f^{''}(x)}$
This algorithm approximates the function J via a linear function that is tangent to J at the current guess θ, solving for where that linear function equals to zero, and doing the next guess for θ be where that linear function is zero.

$\theta = \theta - \frac{J^{'}(\theta )}{J^{''}(\theta )}$
Because theta is vector, applying partial derivative then we have:
$\theta = \theta - \frac{\bigtriangledown _{\theta }J(\theta )}{H}
\Leftrightarrow \theta = \theta - H^{-1}\bigtriangledown _{\theta }J(\theta )\\
\text{where } H_{ij} = \frac{\delta^{2} J(\theta )}{\delta \theta _{i}\theta _{j}} \text{ H is called Hessian matrix and }H\in R^{(n+1)(n+1)}\\
\bigtriangledown _{\theta }J(\theta )=\begin{bmatrix}
\frac{\delta J(\theta )}{\delta \theta _{0}}\\
\frac{\delta J(\theta )}{\delta \theta _{1}}\\
...\\
\frac{\delta J(\theta )}{\delta \theta _{n}}
\end{bmatrix}$
Finally, we have:
$\bigtriangledown _{\theta }J(\theta )=\frac{1}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x^{(i)}\\
H = \frac{1}{m}\sum_{i=1}^{m}\left [ h(x^{(i)})(1-h(x^{(i)}))x^{(i)}(x^{(i)})^{T} \right ]$
Newton method is faster convergence than (batch) gradient descent, and requires many fewer iterations to get very close to the minimum. One iteration of Newton method is more expensive than one iteration of gradient descent, since it requires finding and inverting an Hessian. If number of features is not too large, it is usually much faster. When Newton method is applied, the resulting method is also called Fisher scoring.
Let 's make a demo that reuse the data set of example above:
Running this algorithm we see that after a few iterations the minimum is archived.



2. Classification and logistic regression
3. Optimization methods
3.1 Stochastic / Gradient descent
3.2 Newton method
4. Regularization
1. Introduction
This note focuses on Supervised learning that using Linear regression model and Gradient descent algorithm to build the linear regression model.
Note: python, numpy, basic linear algebra, matplotlib are required. Please refer to this post and this post.
2. Classification and logistic regression
In this topic the prediction value y just takes on only a small number of discrete values. And we only focus on the binary classification problem in which $y \in \left \{ 0, 1 \right \}$. Applying linear regression algorithm to predict y given x, we need a hypothesis that can map y to {0,1}. We define:
$h(x) = g\left ( \theta ^{T}x\right ) = \frac{1}{1 + e^{-\theta ^{T}x}}\\
\text{where: }\\
\theta ^{T}x = \sum_{j=0}^{n}\theta _{j}x_{j} \text{ and } x_{0} = 1\\
g(z) = \frac{1}{1 + e^{-z}} \text{ is called logistic function or sigmoid function}$

Figure: logistic or sigmoid function
From the plot we can see:$g(z)\rightarrow 1 \text{ when } z\rightarrow +\infty \\
g(z)\rightarrow 0 \text{ when } z\rightarrow -\infty \\
g(z) \in \left \{ 0, 1 \right \}$
Moreover, derivation g'(z) = g(z)(1 - g(z))
Change our perspective view to probability view. We consider:
$P(y=1|x; \theta ) = h(x) \text{ probability to y=1 given x, }\theta\\
P(y=0|x; \theta ) = 1 - h(x) \text{ probability to y=0 given x, }\theta\\
\text{or in compact form: } P(y|x; \theta ) = h(x)^{y}(1-h(x))^{1-y}\\
\text{assume m training examples are independent then we have }\\
P(y|x; \theta ) = \prod_{i=1}^{m}P(y^{(i)}|x^{(i)}; \theta ) = h(x^{(i)})^{y^{(i)}}(1-h(x^{(i)}))^{1-y^{(i)}}\\
\text{Apply the log likelihood. We define the log likelihood function:}\\
l(\theta ) = log(P(y|x; \theta )) = \sum_{i=1}^{m}(y^{(i)}log(h(x^{(i)})) + (1-y^{(i)})log(1-h(x^{(i)})))$
When predicting y=1 or y=0 we expect the maximum likelihood that y=1 or y=0. It means we maximize the log likelihood function. We can convert it to equivalent problem, that is minimize "-$l(\theta )$" (inverse problem by multiplying (-1)). We define the cost function:
$J(\theta ) = -l(\theta) = \sum_{i=1}^{m}(-y^{(i)}log(h(x^{(i)})) - (1-y^{(i)})log(1-h(x^{(i)})))$ and try to minimize it. In this post we focus on 2 methods that support to find theta that minimize the cost function: Stochastic / Gradient descent and Newton method.
Why this cost function is better than using 2-norm? If using 2-norm the cost function is not convex and it may have local minimum. While new cost function is convex and has one global minimum.

Figure: new cost function is better
3. Optimization methods
3.1 Gradient descent
We calculate derivation of cost function
$\frac{\delta }{\delta \theta _{j}}J(\theta ) = (h(x) - y)x_{j}$
And then applying stochastic gradient descent rule using partial derivative of J ($\bigtriangledown _{\theta }J(\theta )$):
$\theta = \theta - \alpha \bigtriangledown _{\theta }J(\theta )\\
\text{where }\bigtriangledown _{\theta }J(\theta )=\begin{bmatrix}
\frac{\delta J(\theta )}{\delta \theta _{0}}\\
\frac{\delta J(\theta )}{\delta \theta _{1}}\\
...\\
\frac{\delta J(\theta )}{\delta \theta _{n}}
\end{bmatrix}$
Combine both and apply for 1 training example we have:
$\theta = \theta - \alpha(h(x^{(i)})-y^{(i)})x_{j}$
or batch gradient descent:
$\theta_{j} = \theta_{j} - \alpha\frac{1}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x_{j}^{(i)}$
Let 's make a demo using stochastic gradient descent. The input data is here.
Running this algorithm we see that it takes long time to archive minimum (on my machine it took more than 8 hours)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 | import numpy as np import matplotlib.pyplot as plt from numpy.linalg import inv #we read data from files line by line init = False file = open('demo1x.dat', 'rb') for row in file: r = row.decode('utf8').strip().split(' ') if(init == False): x_train = np.array([[1], [np.float(r[0])], [np.float(r[len(r)-1])]]) init = True else: x_train = np.append(x_train, [[1], [np.float(r[0])], [np.float(r[len(r)-1])]], axis=1); init = False file = open('demo1y.dat', 'rb') for row in file: if(init == False): y_train = np.array([[np.float(row.strip())]]) init = True else: y_train = np.append(y_train, [[np.float(row.strip())]], axis=1); #number of training examples m = y_train.shape[1] #init theta theta = np.array(np.zeros((x_train.shape[0], 1))) #sigmoid function def sigmoid(z): return 1/(1+np.exp(-z)) #we find all indices that make y=1 and y=0 pos = np.flatnonzero(y_train == 1) neg = np.flatnonzero(y_train == 0) #plot data points plt.plot(x_train[1, pos], x_train[2, pos], 'ro') plt.plot(x_train[1, neg], x_train[2, neg], 'bo') x = 0 xT = x_train.T yT = y_train.T preJ = 0 while True: J = 0 x = x + 1; for i in range(0, m): #calculate h, error, cost function for 1 training example h = sigmoid(theta.T.dot(x_train[:,i].T)) error = h.T - yT[i] tmp = (-1)*yT[i]*np.log(h) - (1-yT[i])*np.log((1-h)) #accumulate cost function J = J + tmp nX = np.array([x_train[:,i]]).T #update theta theta = theta - 0.000003*(error*nX) J=J/m #just print cost function for every 1000steps if(x == 1000): x = 0 print(J) if(preJ == 0): preJ = J #condition to stop learning when cost function do not decrease anymore if((preJ) < (J)): break else: preJ = J #we got theta print(theta) #plot the line that separate data poits plot_x = [np.ndarray.min(x_train[1:]), np.ndarray.max(x_train[1:])] plot_y = np.subtract(np.multiply(-(theta[2][0]/theta[1][0]), plot_x), theta[0][0]/theta[1][0]) plt.plot(plot_x, plot_y, 'b-') plt.show() |

Figure: Stochastic gradient descent
3.2. Newton methodIn order to find theta that maximize likelihood of cost function, we need to find theta so that $\frac{\delta }{\delta \theta _{j}}J(\theta ) = 0$.
The Newton method supports to find the value of x so that the function f(x) = 0 by applying repeating calculation:
$x _{t+1} = x _{t} - \frac{f^{'}(x)}{f^{''}(x)}$
This algorithm approximates the function J via a linear function that is tangent to J at the current guess θ, solving for where that linear function equals to zero, and doing the next guess for θ be where that linear function is zero.

Figure: How it works (source)
Apply for our problem, we have:$\theta = \theta - \frac{J^{'}(\theta )}{J^{''}(\theta )}$
Because theta is vector, applying partial derivative then we have:
$\theta = \theta - \frac{\bigtriangledown _{\theta }J(\theta )}{H}
\Leftrightarrow \theta = \theta - H^{-1}\bigtriangledown _{\theta }J(\theta )\\
\text{where } H_{ij} = \frac{\delta^{2} J(\theta )}{\delta \theta _{i}\theta _{j}} \text{ H is called Hessian matrix and }H\in R^{(n+1)(n+1)}\\
\bigtriangledown _{\theta }J(\theta )=\begin{bmatrix}
\frac{\delta J(\theta )}{\delta \theta _{0}}\\
\frac{\delta J(\theta )}{\delta \theta _{1}}\\
...\\
\frac{\delta J(\theta )}{\delta \theta _{n}}
\end{bmatrix}$
Finally, we have:
$\bigtriangledown _{\theta }J(\theta )=\frac{1}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x^{(i)}\\
H = \frac{1}{m}\sum_{i=1}^{m}\left [ h(x^{(i)})(1-h(x^{(i)}))x^{(i)}(x^{(i)})^{T} \right ]$
Newton method is faster convergence than (batch) gradient descent, and requires many fewer iterations to get very close to the minimum. One iteration of Newton method is more expensive than one iteration of gradient descent, since it requires finding and inverting an Hessian. If number of features is not too large, it is usually much faster. When Newton method is applied, the resulting method is also called Fisher scoring.
Let 's make a demo that reuse the data set of example above:
Running this algorithm we see that after a few iterations the minimum is archived.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | import numpy as np import matplotlib.pyplot as plt from numpy.linalg import inv init = False file = open('logistic_x.txt', 'rb') for row in file: r = row.decode('utf8').strip().split(' ') if(init == False): x_train = np.array([[1], [np.float(r[0])], [np.float(r[len(r)-1])]]) init = True else: x_train = np.append(x_train, [[1], [np.float(r[0])], [np.float(r[len(r)-1])]], axis=1); init = False file = open('logistic_y.txt', 'rb') for row in file: if(init == False): y_train = np.array([[np.float(row.strip())]]) init = True else: y_train = np.append(y_train, [[np.float(row.strip())]], axis=1); m = y_train.shape[1] theta = np.zeros((x_train.shape[0], 1)) def sigmoid(z): return 1/(1+np.exp(-z)) pos = np.flatnonzero(y_train == 1) neg = np.flatnonzero(y_train == 0) plt.plot(x_train[1, pos], x_train[2, pos], 'ro') plt.plot(x_train[1, neg], x_train[2, neg], 'bo') yT = y_train.T xT = x_train.T #iterator 500 steps for x in range(0, 10): h = sigmoid(theta.T.dot(x_train)) error = h - y_train tmp = (-1)*y_train*np.log(h) - (1-y_train)*np.log((1-h)) J = np.sum(tmp)/m; #calculate H H = (h*(1-h)*(x_train)).dot(x_train.T)/m #calculate dJ dJ = np.sum(error*x_train, axis=1)/m #gradient = H-1.dJ grad = inv(H).dot(dJ) #update theta theta = theta - (np.array([grad])).T print(J) print(theta) plot_x = [np.ndarray.min(x_train[1:]), np.ndarray.max(x_train[1:])] plot_y = np.subtract(np.multiply(-(theta[2][0]/theta[1][0]), plot_x), theta[0][0]/theta[1][0]) plt.plot(plot_x, plot_y, 'b-') plt.show() |

Figure: logistic regression using Newton method

Comparing between 2 methods
Stochastic / Gradient descent:
- Need to choose learning rate
- Need more iterations
- Each iteration is cheaper
- Use when n is large
Newton method:
- No parameters
- Need fewer iterations
- Each iteration more expensive, we need more calculations $H, H^{-1} \text{ where } H\in R^{(n+1)(n+1)}$
- Use when n is small
If n<1000: use Newton method
If 1000<n<10.000: choose the best one in 2 methods
If n>10.000: use Stochastic/Gradient descent
4. Regularization
In order to avoid overfiting we use regularization.

Figure: overfitting - the black curve fit perfectly data set using complex h(x)
Using regularization we adjust old cost function and updating rules:
Stochastic / Gradient descent:
$J(\theta ) = \left [ \sum_{i=1}^{m}(-y^{(i)}log(h(x^{(i)})) - (1-y^{(i)})log(1-h(x^{(i)}))) \right ] + \frac{\lambda}{2m} \sum_{j=1}^{n}\theta _{j}^{2}\\
\text{Stochastic gradient descent rules:}\\
\theta_{0} = \theta_{0} - \alpha(h(x^{(i)})-y^{(i)})x_{0}^{(i)}\\
\theta_{j} = \theta_{j} - \alpha(h(x^{(i)})-y^{(i)})x_{j}^{(i)} - \frac{\lambda }{m}\theta _{j}\\
\text{Gradient descent rules:}\\
\theta_{0} = \theta_{0} - \frac{\alpha}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x_{0}^{(i)}\\
\theta_{j} = \theta_{j} - \frac{\alpha}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x_{j}^{(i)}- \frac{\lambda }{m}\theta _{j}$
\text{Stochastic gradient descent rules:}\\
\theta_{0} = \theta_{0} - \alpha(h(x^{(i)})-y^{(i)})x_{0}^{(i)}\\
\theta_{j} = \theta_{j} - \alpha(h(x^{(i)})-y^{(i)})x_{j}^{(i)} - \frac{\lambda }{m}\theta _{j}\\
\text{Gradient descent rules:}\\
\theta_{0} = \theta_{0} - \frac{\alpha}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x_{0}^{(i)}\\
\theta_{j} = \theta_{j} - \frac{\alpha}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x_{j}^{(i)}- \frac{\lambda }{m}\theta _{j}$
Newton method:
$\bigtriangledown _{\theta }J(\theta )=\begin{bmatrix}
\frac{1}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x_{0}^{(i)}\\
\frac{1}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x_{1}^{(i)} - \frac{\lambda }{m}\theta _{1}\\
...\\
\frac{1}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x_{n}^{(i)}- \frac{\lambda }{m}\theta _{n}
\end{bmatrix} \in R^{n+1}\\
H = \frac{1}{m}\sum_{i=1}^{m}\left [ h(x^{(i)})(1-h(x^{(i)}))x^{(i)}(x^{(i)})^{T} \right ] + \frac{\lambda }{m}\begin{bmatrix}
0 & 0 & 0 & 0 & 0\\
0 & 1 & 0 & 0 & 0\\
0 & 0 & 1 & 0 & 0\\
. & . & . & . & .\\
0 & 0 & 0 & 0 & 1
\end{bmatrix} \in R^{(n+1)(n+1)}$
Let 's make demos for Newton method:
\frac{1}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x_{0}^{(i)}\\
\frac{1}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x_{1}^{(i)} - \frac{\lambda }{m}\theta _{1}\\
...\\
\frac{1}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x_{n}^{(i)}- \frac{\lambda }{m}\theta _{n}
\end{bmatrix} \in R^{n+1}\\
H = \frac{1}{m}\sum_{i=1}^{m}\left [ h(x^{(i)})(1-h(x^{(i)}))x^{(i)}(x^{(i)})^{T} \right ] + \frac{\lambda }{m}\begin{bmatrix}
0 & 0 & 0 & 0 & 0\\
0 & 1 & 0 & 0 & 0\\
0 & 0 & 1 & 0 & 0\\
. & . & . & . & .\\
0 & 0 & 0 & 0 & 1
\end{bmatrix} \in R^{(n+1)(n+1)}$
Let 's make demos for Newton method:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 | import numpy as np import matplotlib.pyplot as plt from numpy.linalg import inv #we read data from files line by line init = False file = open('demo2x.dat', 'rb') for row in file: r = row.decode('utf8').strip().split(',') if(init == False): x1 = np.array([np.float(r[0])]) x2 = np.array([np.float(r[1])]) init = True else: x1 = np.append(x1, [np.float(r[0])]) x2 = np.append(x2, [np.float(r[1])]) init = False file = open('demo2y.dat', 'rb') for row in file: if(init == False): y_train = np.array([[np.float(row.strip())]]) init = True else: y_train = np.append(y_train, [[np.float(row.strip())]], axis=1); def sigmoid(z): return 1/(1+np.exp(-z)) def create_feature(x1, x2): x_train = np.array([np.ones(len(x1))]) for total in range(1, 7): for p in range(total, -1, -1): x_train = np.append(x_train, [np.power(x1, p)*np.power(x2, total-p)], axis=0) return x_train x_train = create_feature(x1, x2) #number of training examples m = y_train.shape[1] #init theta theta = np.array(np.zeros((x_train.shape[0], 1))) pos = np.flatnonzero(y_train == 1) neg = np.flatnonzero(y_train == 0) plt.plot(x_train[1, pos], x_train[2, pos], 'ro') plt.plot(x_train[1, neg], x_train[2, neg], 'bo') #modify lamda to see results lamda = 1 one = np.identity(x_train.shape[0]) one[0,0] = 0 for x in range(0, 15): h = sigmoid(theta.T.dot(x_train)) error = h - y_train tmp = (-1)*y_train*np.log(h) - (1-y_train)*np.log((1-h)) J = np.sum(tmp)/m + lamda*theta[1::,0].T.dot(theta[1::,0])/2*m #calculate H with regularization from 1 H = (h*(1-h)*(x_train)).dot(x_train.T)/m + lamda*one/m #calculate dJ with regularization from 1 dJ = np.sum(error*x_train, axis=1)/m dJ[1:] = dJ[1:] - lamda*theta.T[0,1::]/m #gradient = H-1.dJ grad = inv(H).dot(dJ) #update theta theta = theta - (np.array([grad])).T print(J) print(theta) #plot boundary u = np.linspace(-1, 1.5, 200) v = np.linspace(-1, 1.5, 200) #create input grid uu, vv = np.meshgrid(u, v, sparse=False) #output contour plotz = np.zeros(uu.shape) #evaluate z for i in range(0, len(uu)): z = theta.T.dot(create_feature(uu[i], vv[i])) for j in range(0,z.shape[1]): plotz[i][j] = z[0][j] #plot contour plt.contourf(uu, vv, plotz, linestyles='dashed') plt.show() |

Figure: no regularization, the hypothesis fit perfectly

Figure: with regularization and lamda=1, eliminate overfitting

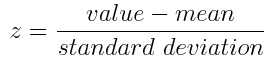





{kind=link}
5 Comments
Useful content, I have bookmarked this page for my future reference.
ReplyDeleteccna Training in Chennai
ccna course in Chennai
Python Classes in Chennai
Python Training Institute in Chennai
R Training in Chennai
R Programming Training in Chennai
CCNA Training in T Nagar
CCNA Training in Adyar
Thanks to the admin for sharing this blog with us. The info in this blog was really helpful to me.
ReplyDeletegerman classes in mulund
german language classes in mulund
german classes in mulund west
German Course in Mulund East
French Classes in Mulund
French Classes in Mulund East
French Classes in Mulund West
French Language Classes in Mulund
I have been continuously reading all your blogs. You have shared a worthy information.
ReplyDeleteSpoken English Class in Thiruvanmiyur
Spoken English Classes in Adyar
Spoken English Classes in T-Nagar
Spoken English Classes in Vadapalani
Spoken English Classes in Porur
Spoken English Classes in Anna Nagar
Spoken English Classes in Chennai Anna Nagar
Spoken English Classes in Perambur
Spoken English Classes in Anna Nagar West
Well written Blog, I really enjoy reading your blog. this info will be helpful for me. Thanks for sharing.
ReplyDeleteccna Training in Chennai
ccna institute in Chennai
Angularjs Training in Chennai
gst classes in chennai
ux design course in chennai
PHP Training in Chennai
Web Designing Course in Chennai
ccna course in chennai
ccna training in chennai
Great, post is so informative and helpfull to everyone , keep posting and checkout my blog java course in pune
ReplyDelete